常用进制及相互转换
常用进制及相互转换
数制概念
数制也称为计数制,是一种计数的方法,用一组固定的符号和统一的规则来表示数值的方法。在计数过程中采用进位的方法称为进位计数制(进制),包括数位、基数和位权三个要素。
- 数位:指数字符号在一个数中所处的位置。
- 基数:指在某种进位计数制中数位上所能使用的数字符号的个数。(例如十进制的基数为10)
- 位权:数制中某一位上的1所表示数值的大小(所处位置的价值)。(例如十进制的567,5的位权是100,6的位权是10,7的位权是1)
进制概念
进制就是进位计数制,是人为定义的带进位的计数方法。对于任何一种进制—X进制,每一位上的数做运算时都是逢X进一(借位时借一当X),各数位上的数字可以使用0,1,...X - 1共 X 个数字来表示。
常用进制
十进制

在人类自发采用的进位制中,十进制是使用最为普遍的一种。成语 “屈指可数” 某种意义上来说描述了一个简单计数的场景,而原始人类在需要计数的时候,首先想到的就是利用天然的算筹—手指来进行计数。十进制的基数为10,数位上的数字由0~9组成。
二进制

计算机领域之所以采用二进制进行计数,主要是因为二进制只有两个数码0和1,可用具有两个不同稳定状态的元器件来表示一位数码;其次是二进制数运算简单,大大简化了计算中运算部件的结构。二进制的基数为2,数位上的数字只由0或1组成,运算规律为逢二进一。
八进制

在中国古代哲学体系中,八卦是由三个阴阳符号组成的八个图案。这些图案被用来表示天、地、水、火、风、雷、山、泽等自然元素,也被用来描述人类的行为和情感。
在计算机科学中,由于二进制数据的基数较小,所以二进制数据的书写和阅读不方便,为此在小型机中引入八进制。八进制的基数为8,数位上的数字由0~7组成,一位八进制数字刚好对应三位二进制数,可以很好地反映二进制。
十六进制
“半斤八两”、“一斤十六两” 是自秦始皇制定统一度量衡后,采用十六进位制作为斤两的计量单位。直到清朝末年,为了与国际计量体系接轨,正式废除了十六两制。
计算机中采用十六进制,一方面是因为每四位二进制数字可以直接映射到一个十六进制数字,可以实现数据的压缩和简化,同时减少所需的空间和带宽,易于人机交互和阅读;其次是在底层编程中,十六进制允许开发者更直接地访问和操作内存和寄存器,使用十六进制可以更容易地调试和识别数据模式。
十六进制是由数字0~9加上字母A ~ F组成(分别对应十进制数10~15),十六进制数运算规律是逢十六进一。
各进制间对应关系

进制转换
1. 十进制转换为 X 进制
整数部分:“除 X 取余,逆序排列”
【1】 将 X 作为除数,用十进制整数除以 X,可以得到一个商和余数; 【2】保留余数,用商继续除以 X,又得到一个新的商和余数; ...... 【3】如此反复进行,每次都保留余数,用商接着除以 N,直到商为 0 时为止。 【4】先得到的余数作为 X 进制数的低位数字,后得到的余数作为 X 进制数的高位数字,依次排列起来。
【例】将十进制数字 42 转为二进制

(42)10(42)10 = (101010)2(101010)2。
小数部分:“乘 X 取整,顺序排列” 【1】将十进制小数部分乘以 X,乘完后将乘积的整数部分取出; 【2】余下的小数部分继续乘以 X ,再将新乘积的整数部分取出; ...... 【3】如此反复进行,每次都取出整数部分,用剩下的小数部分接着乘以 X,直到乘积中的小数部分为 0,或者达到所要求的精度为止。 【4】把取出的整数部分按顺序排列起来,先取出的整数作为 X 进制小数的高位数字,后取出的整数作为低位数字。
【例】将十进制数字 0.6875 转为二进制

(0.6875)10(0.6875)10 = (0.1011)2(0.1011)2。
注:绝大部分浮点数无法用二进制精确表示
2. X 进制转换为十进制
方法:“按权展开求和”
【1】对于整数部分,从右往左看,第 i 位的位权等于Xi−1X**i−1;
【2】对于小数部分,从左往右看,第 j 位的位权为X−jX−j。
【3】把每个数位上数值与对应的位权相乘后,将乘积相加求和。
【例】将八进制数字 53627 转换成十进制
(53627)8(53627)8 = 5×84+3×83+6×82+2×81+7×805×84+3×83+6×82+2×81+7×80 = (22423)10(22423)10
【例】将十六进制数字 9FA8C 转换成十进制
(9FA8C)16(9F**A8C)16 = 9×164+15×163+10×162+8×161+12×1609×164+15×163+10×162+8×161+12×160 = (653964)10(653964)10
【例】将二进制数字 1010.1101 转换成十进制
(1010.1101)2(1010.1101)2 = 1×23+0×22+1×21+0×20+1×2−1+1×2−2+0×2−3+1×2−41×23+0×22+1×21+0×20+1×2−1+1×2−2+0×2−3+1×2−4 = (10.8125)10(10.8125)10
3. 二进制转为八或十六进制
二转八:“三合一”
【整数部分】从低位向高位每三个二进制数分为一组,转换成一位八进制数字。高位不足三位前补零。
【小数部分】从高位向低位每三个二进制数分为一组,转换成一位八进制数字。低位不足三位后补零。
【例】将二进制整数 1110111100 转换为八进制

(1110111100)2(1110111100)2 =(1674)8(1674)8
二转十六:“四合一”
【整数部分】从低位向高位每四个二进制数分为一组,转换成一位十六进制数字。高位不足四位前补零。
【小数部分】从高位向低位每四个二进制数分为一组,转换成一位十六进制数字。低位不足四位后补零。
【例】将二进制整数 10 1101 0101 1100 转换为十六进制

(10110101011100)2(10110101011100)2 = (2D5C)16(2D5C)16
4. 八或十六进制转为二进制
八转二:“一分三”
将每一位八进制数字转换为三位二进制数字,把转换后的二进制数字拼在一起后,分别抹掉整数部分的高位零和小数部分的末尾零。
【例】将八进制整数 2743 转换为二进制

(2743)8(2743)8 = (10111100011)2(10111100011)2
十六转二:“一分四”
将每一位十六进制数字转换为四位二进制数字,把转换后的二进制数字拼在一起后,分别抹掉整数部分的高位零和小数部分的末尾零。
【例】将十六进制整数 A5D6 转换为二进制

(A5D6)16(A5D6)16 = (1010010111010110)2(1010010111010110)2
注:八进制与十六进制间无法直接转换,需要借助二或十进制作为桥梁。
数据编码
机器数
一个数在计算机中的二进制表示形式,叫做这个数的机器数。机器数具备两个特点:
【1】符号数字化,实数有正数和负数之分,计算机内部硬件只能表示两种物理状态(0和1),因此数的正号或负号在计算机里需要用一位二进制来区别。在计算机用机器数的最高位存放符号,以0代表符号“+”,以1代表符号“-”。
【2】数字大小受机器字长的限制:机器内部设备一次能表示的二进制位数叫机器的字长,一台机器的字长是固定的。字长8位(bit)叫一个字节(Byte),机器字长一般都是字节的整数倍,如字长8位、16位、32位、64位。
例如当计算机字节长为8位时,十进制 +5 转换为二进制就是 0000 0101,十进制- 5 转换为二进制就是1000 0101,这里的 0000 0101和1000 0101就是机器数。
真值
因为第一位是符号位,所以机器数的形式值就不等于真正的数值。
例如上面的有符号数 1000 0011,其最高位1代表负,其真正数值是 -3,而不是形式值131(1000 0011转换成十进制等于131)。所以为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
例如 0000 0001的真值 = +000 0001 = +1,1000 0001的真值 = –000 0001 = –1
对于一个数字,计算机要使用一定的编码方式进行存储,原码、反码、补码是机器存储一个具体数字的3种具体编码方式。
原码
原码的表示方法是:最高位为符号位,0代表正数,1代表负数,非符号位用该数字绝对值的二进制表示。原码是人脑最容易理解和计算的表示方式。
例如当计算机字节长为8位时,[+1]原= 0000 0001,[-1]原= 1000 0001
第一位是符号位,只表示正负,8位二进制数原码的取值范围是:[1111 1111 , 0111 1111],即[-127 , 127]
反码
反码的表示方法是:正数的反码是其本身;负数的反码是在其原码的基础上,符号位不变,其余位取反。
例如[+1] = [0000 0001]原= [0000 0001]反,[-1] = [1000 0001]原= [1111 1110]反;
如果一个反码表示的是负数,人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
8位二进制数反码的取值范围时:[1000 0000 , 0111 1111],即[-127 , 127]
补码
补码的表示方法是:正数的补码就是其本身;负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
[+1] = [0000 0001]原= [0000 0001]反= [0000 0001]补
[-1] = [1000 0001]原= [1111 1110]反= [1111 1111]补
对于负数,补码表示方式也是人脑无法直观看出其数值的。也需要转换成原码再计算其数值。
8位二进制数补码的取值范围是:[1000 0000 , 0111 1111],即[-128 , 127]
1、所以正数的原码、反码、补码都相同。
2、计算机中负数都是以补码形式存在的。
在补码运算中,[1000 0000]补其实就是-128,但实际上将以前的 -0 表示为-128的补码形式,所以-128并没有原码和反码表示。(对-128的补码表示[1000 0000]补,算出来的原码是[0000 0000]原,是不正确的)
使用补码,不仅仅修复了0的符号以及存在两个编码的问题,而且还能够多表示一个最低数。这就是为什么8位二进制,使用原码或反码表示的范围为[-127, +127],使用补码表示的范围为[-128, 127]。
同理对于常用到的有符号的32位int类型,可以表示范围是: [−231,231−1][−231,231−1] 。
位运算
概念
计算机中的数在内存中都是以二进制形式进行存储的 ,位运算是将每个二进制位作为 布尔值,分别对一个或两个二进制数中对应的二进制位做布尔运算。
注意:在手动进行 位运算计算 时,需要将数转换成二进制的表示形式,再进行计算。如 3 & 5,先写成二进制形式的 0011 和 0101,右边最低位对齐后再分别对相应位进行位运算。
位运算规则介绍

位运算常用性质
【简单规则】
(1)a 与自身之间的操作
a & a = a;
a | a = a;
a ^ a = 0;
(2)a 与 0 之间的操作
a & 0 = 0;
a | 0 = a;
a ^ 0 = a;
(3)还原计算
a | ( a & b ) = a;
a & ( a | b ) = a;
【基础性质】
“清零取反要用与,某位置一可用或。若要取反和交换,轻轻松松用异或”
(4)判断奇偶
// 通过 & 1 取出最后一个二进制位以达到模 2 的效果,位运算效率更高
if(a & 1 == 1)//奇数
if(a & 1 == 0)//偶数
//同(a % 2)
(5)比较两个整数是否相等
a ^ b//如果结果为0则为相等,反之不等
(6)正整数乘或除以 2x2x
a = a << x;//乘以2^x;
a = a >> x;//除以2^x;
(7)交换两个整数
a ^= b;
b ^= a;
a ^= b;
【高阶延展】
(8)取出 a 中倒数第 i 个二进制位上的数值
a & (1 << (i - 1)); 或 (a >> (i - 1)) & 1
(9)计算 a 的相反数
a = ~a + 1;//数字取反后等于其相反数-1
(10)保留 a 在二进制位中最后一个 1
a &= (-a);//获取最低位位权,常用在lowbit()函数中
(11)删除 a 二进制序列中最后一个值为 1 的位置
a &= (a - 1);//如果结果为0,则说明a是2的指数
(12)将 a 的倒数第 i 位二进制位设为 1
a |= 1 << (i - 1);
(13)将 a 的倒数第 i 位二进制位设为 0
a &= ~(1 << (i - 1)));
(14)保留 a 二进制序列中最后的 i 位,其余补 0
a &= ((1 << i) - 1);
(15)将 a 二进制序列中最后 i 位全部置为 0
a &= ~((1 << i) - 1)
(16)求 a 取模 2x2x 后的结果
a=a&(2x−1)a=a&(2x−1); 同 a%=2xa%=2x
运算符优先级



数组
概念
可以用来存储一系列同种类型的数据,并且这些数据在内存中是连续存储的。(线性结构、顺序结构)
定义
1. 数据类型 数组名[数组长度];
2. 数据类型 数组名[数组长度] = {值1, 值2...};
3. 数据类型 数组名[ ] = {值1,值2...};
声明及初始化
int a[1005]; //如果定义在主函数之上,数组a所有元素的值赋为0
int b[5]={1,2,3,4.5};//b[0]、b[1]、b[2]、b[3]、b[4]的值分别赋为1,2,3,4,5
int c[5]={1,2,3}; //c[0]、c[1]、c[2]、c[3]、c[4]的值分别赋为1,2,3,0,0
int d[5]={0}; //将数组d中5个元素的值全赋为0
int e[]={1,2,3}; //e[0]、e[1]、e[2]的值分别赋为1,2,3,且将数组的长度定义为3
【注意事项】
1.局部数组默认值为野值,全局数组默认值为0;
2.数组长度可以使是一个常量或包含运算符的表达式;
int n = 10;
int a[n];//此定义方式并不适合所有的编译器, 只有支持 C99 标准的编译器才支持这种定义方式, 否则在编译时会报错
3.大数组须定义为全局数组,在局部定义大数组会爆栈;
使用
数组名[下标]
数组下标从0的位置开始,下标最大值为数组长度减1。
例如a[0]、b[1]、c[b[i]]、d['L']
只能逐个引用数组元素的值,而不能一次引用整个数组中全部元素的值。
【注意事项】
1.数组名是常量,不可以进行赋值操作;整型数组输出数组元素时,输出数组名得到的是首元素地址而不是批量元素。
2.使用数组时下标不能越界(上界和下界),否则会造成内存的混乱,但不会导致编译错误;
计算占用空间
计算数组占用内存总空间的大小,主要有两种方式
①数组相当于有多个变量组成,可以通过单个数组元素所占用的空间乘以数组长度
②也可以使用sizeof(数组名)得到整个数组占用的内存大小
int array[10];
printf("array占用的内存大小为=%d\n",sizeof(array)); // i占用的内存大小为=40
printf("int占用的内存大小为=%d\n",sizeof(int) * 10); // int占用的内存大小为=4
字符串函数
概念
字符串是一个接一个字符的一组字符连在一起(类似于用一根冰糖葫芦串起了很多山楂球),所以字符串的基本组成元素是字符。
储存
存储字符串比如"jack"时,有两种不同的方式,一种是字符型数组,另一种是string类。
char a[5] = "jack";
在字符串中使用标识符'\0'作为结束标志,结束符'\0'也需要占用一个存储位,所以声明数组时长度至少为5。等同于:
char a[5] = {'j', 'a', 'c', 'k', '\0'};
【注意事项】
1.由 n 个字符个数组成的字符串在内存中应占( n+1 )个字节。
2.'0'代表字符0,对应ASCII码值为48,'\0'代表空字符(转义字符),对应ASCII码值为0。
输入与输出
方法1:可以使用%s整体输入输出(不保存空白符,如空格、回车、换行符等)
方法2:利用循环结合下标逐次操作
#include <cstdio>
int main(){
char a[10];
scanf("%s", a);//无需加&
printf("%s", a);
return 0;
}
函数
(1)字符转换
判断字符ch是否为小写字符,如果是转为大写字符
//方法1:
if (ch >= 'a' && ch <= 'z') 或 if (ch >= 97 && ch <= 122)
ch = ch - 'a' + 'A';//或ch -= 32;
//方法2:<cctype>头文件下
if (islower(ch)) {
toupper(ch);
}
判断一个字符ch是否为大写字符,如果是转为小写字符
//方法1:
if (ch >= 'A' && ch <= 'Z') 或 if (ch >= 65 && ch <= 90)
ch = ch - 'A' + 'a';//或ch += 32;
//方法2:<cctype>头文件下
if (isupper(ch)) {
tolower(ch);
}
判断一个是否为数字字符
//方法1:
if (ch >= '0' && ch <= '9') 或 if (ch >= 48 && ch <= 57)
//方法2:<cctype>头文件下
if (isdigit(a[i]))
(2)获取长度
使用strlen()可以计算字符串中有效字符个数(不包括'\0')
char a[5] = "jack";
cout << strlen(a);//4
(3)替换
通过strcpy(a, b) 来把复制字符型数组b内的信息,并替换掉数组a保存的字符串。(返回值是数组a首字符的指针)
char a[5] = "jack", b[5] = "rose";
strcpy(a, b);
cout << a;//rose
(4)拼接
使用strcat(a, b)可以把字符型数组b保存的信息连接在原数组a保存的之后。(返回值是数组a首字符的指针)
char a[10] = "jack", b[5] = "rose";
strcat(a, b);
cout << a;//jackrose
(5)比较大小
使用strcmp(a, b)按照字典序逐位比较对应位置的字符大小,如果字符相同继续向后进行比较,若不同返回比较后的结果。如果比较结果小于0,则a < b;如果比较结果为0,则a = b;如果比较结果大于0,则a > b;
char a[10] = "jcak", b[5] = "rose";
cout << strcmp(a, b) << endl;// < 0
cout << strcmp(b, a) << endl;// > 0
算法概念
基本概念
算法(Algorithm)是指解题方案的准确而完整的描述。在计算机科学领域中算法几乎无处不在,在各种计算机系统的实现中,算法的设计往往处于核心的位置。
算法特征
| 特性 | 描述 |
|---|---|
| 有穷性 | 有穷性是指必须能在执行有限个步骤之后结束,并且每一步都可以在有限的时间内完成 |
| 确切性 | 每一个步骤必须具有确切的定义,是无二义性的 |
| 输入性 | 一个算法有0个或多个输入(所谓0个输入是指算法本身就嵌入了输入) |
| 输出性 | 一个算法必须具有一个或多个输出,以反映算法对输入数据加工后的结果 |
| 可行性 | 任何操作都是可以被分解为基本的可执行的步骤 |
标准
| 标准 | 介绍 |
|---|---|
| 正确性 | 正确性是指在合理的数据输入下,能在有限的时间内得出正确的结果 |
| 可读性 | 算法主要是为了人的阅读与交流,其次才是让计算机执行,因此算法应该易于人的理解 |
| 健壮性 | 算法应当具备检查错误和对错误进行适当处理的能 |
| 效率 | 指算法执行时所需计算机资源的多少,包括运行时间和存储空间两方面的要求(时间复杂度、空间复杂度) |
描述方式
自然语言描述
自然语言法是指用文字叙述的形式描述集合的方法。自然语言来描述算法的优点是更便于对算法的理解和阅读,缺点是不够严谨易产生歧义。当使用自然语言描述比较复杂的结构算法时,就不够直观清晰了。
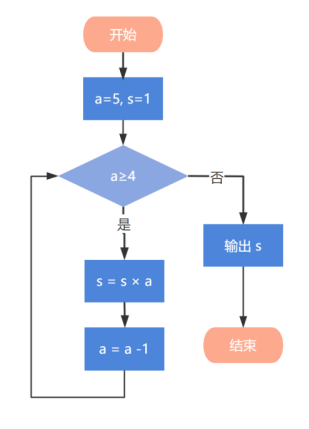
流程图
使用特定图形符号加上文字说明表示具体流程和算法思路的一种框图,通俗地讲就是“流程”+“图”。除了说明程序的流程顺序外,着重于说明程序的逻辑性。

伪代码描述
伪码语言介于高级程序设计语言和自然语言之间,它忽略高级程序设计语言中一些严格的语法规则与描述细节,因此它比程序设计语言更容易描述和被人理解,而且比自然语言或算法框图更接近程序设计语言。
高级程序设计语言描述法
使用特定的可以直接在计算机上执行的程序描述算法。优点是不用转换直接可以编译执行,缺点是需要对特定的程序设计语言比较理解。(所谓“程序”是指对所要解决问题的各个对象和处理规则的描述,或者说是数据结构和算法的描述,因此有人说 数据结构+算法=程序)
算法设计方法主要有分治策略、动态规划、贪心算法、回溯法、搜索、概率算法等。
模拟法
现实生活中有些问题难以找到公式或规律来求解,只能 按照一定的步骤不停的模拟 下去, 最后才能得到答案。 这样的问题用计算机求解十分合适,只要能让计算机模拟人在解决此问题时的行为即可。 这种求解问题的思想,称为模拟。
枚举法
基本思想
逐一列举问题所涉及的所有情形,并根据问题提出的条件检验排查出是问题的解。(也称为列举法、穷举法,是暴力策略的具体体现)
特点
(1)枚举算法的思路简单,正确性容易证明,方便程序编写和调试
(2)当问题的规模变大的时候,运算量过大,执行速度越慢,解题效率不高
解题步骤
(1)确定枚举对象;
(2)确定枚举范围和判断条件;
(4)逐一筛选出问题的解。
常用语法:循环+判断语句。
优化
由于枚举法对要所有可能的情况进行筛选,不重复不遗漏地进行检验,通过牺牲时间来换取答案的全面性。为此优化的主要方向是:
(1)减少状态总数,从而减少计算量;
(2)将原问题化为更小的问题,根据问题的性质进行剪枝;
【经典例题】求极值问题、百元买百鸡、阿斯特朗数
单选题(2分)全站正确率 87%
下列流程图的输出结果是?( )
-
A
60
-
B
20
-
C
5
-
D
1